[OS] Chapter 5 — Process Scheduling
Basic Concepts
因為 multiprogramming 所以才要 scheduling。
CPU-I/O burst cycle
→ 東西要嘛在 CPU 要嘛在 I/O

所以每一個 process 就切成在 CPU burst 和在 I/O burst
I/O-bound program → 大部分在做 I/O
⇒ 不等於 I/O burst 的 cycle 數比 CPU 多(數量應該要是一樣的,因為一個做完接另一個),應該要是一個 burst 要很久。
CPU-bound program → 大部分在做 CPU
CPU 大多是短的 burst 很多

CPU Scheduler
Ready state → Running state
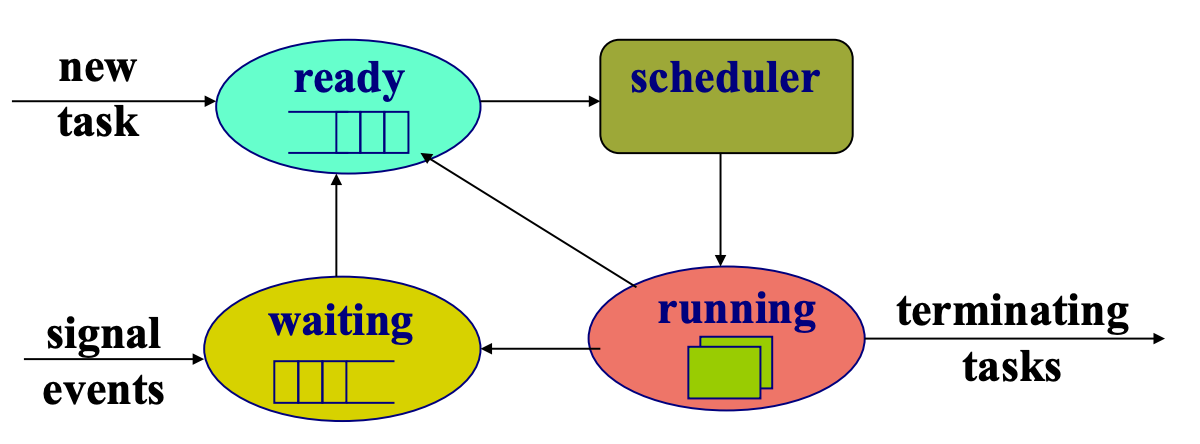
下面都假設是 single core,只有單一隻程式
Preemptive vs. Non-preemptive
- Preemptive → 一個 process 可以在 CPU burst 中間被打斷
- Non-preemptive → 一個 process 不能在 CPU burst 中間被打斷,一定要做完的
- CPU scheduling 要做事的時間點:
- A process switch from running to waiting → CPU 空下來了,可以加東西囉
- A process switch from running to ready(可能是 timer 到了,所以被丟過去了)→ CPU 空下來了,可以加東西囉
- A process switch from waiting to ready → 看看有沒有更重要,需要就把 running 的拿掉換他
- A process terminates → CPU 空下來了,可以加東西囉
- 紫色是 Non-preemptive 的 scheduler 只能做的事
- 大部分都是 preemptive。(Windows, Mac OS)
- Preemptive issue
- 會打斷東西,所以可能會 raise condition(如果不打斷就不會產生)
- 會影響到 OS 需不需要處理 synchronisation 的問題
- Unix solution: 進到 kernel space 就 disable 2 和 3(就會變成 non-preemptive)
Dispatcher
- 把 scheduler 選出來的東西丟到 CPU 裡面的苦工。(Switching context...)
- 要很有效率
Scheduling Algorithms
- Scheduling Criteria → 定義效能的指標
- CPU utilization
- 0% ~ 100% (per core)
- 通常大概會在 40% ~ 90% 之間
- Throughput
- 每單位時間可以完成多少工作(processes)
- High throughput computer system → 目標就是要最大化 through 的 computer system
- 很常見,比 utilization 重要(對 user 來講比較有感覺)
- Turnaround time
- 單一 process 的角度來量測
- 進到 new 到 terminate 的時間(submission ~ completion)
- 通常會看平均、最大值、最小值、distribution 等等
- Waiting time
- 在 ready queue 的總時間(不包括 waiting time)
- 是純粹因為 scheduling 的原因所以不能執行
- Response time
- new 到第一次回應(第一次進到 running)
- CPU utilization
First-Come, First-Served (FCFS) scheduling
先來先排
會給 CPU burst time,根據他們進來的順序
Example
- P1(24), P2(3), P3(3)
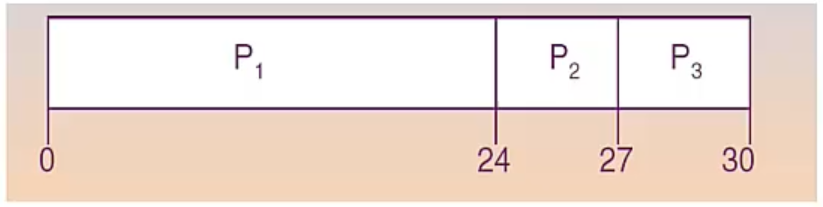
- Waiting time: P1 = 0, P2 = 24, P3 = 27
- Average Waiting Time (AWT): (0 + 24 + 27) / 3 = 17
Convoy effect (Head of line blocking): 可以很快執行的被要跑很久的擋住了
Shortest-Job-First (SJF) scheduling
Optimal solution → minimum average waiting time
最短 CPU burst time 的先做
Two schemes
- Non-preemptive
- Preemptive
Non-preemptive example

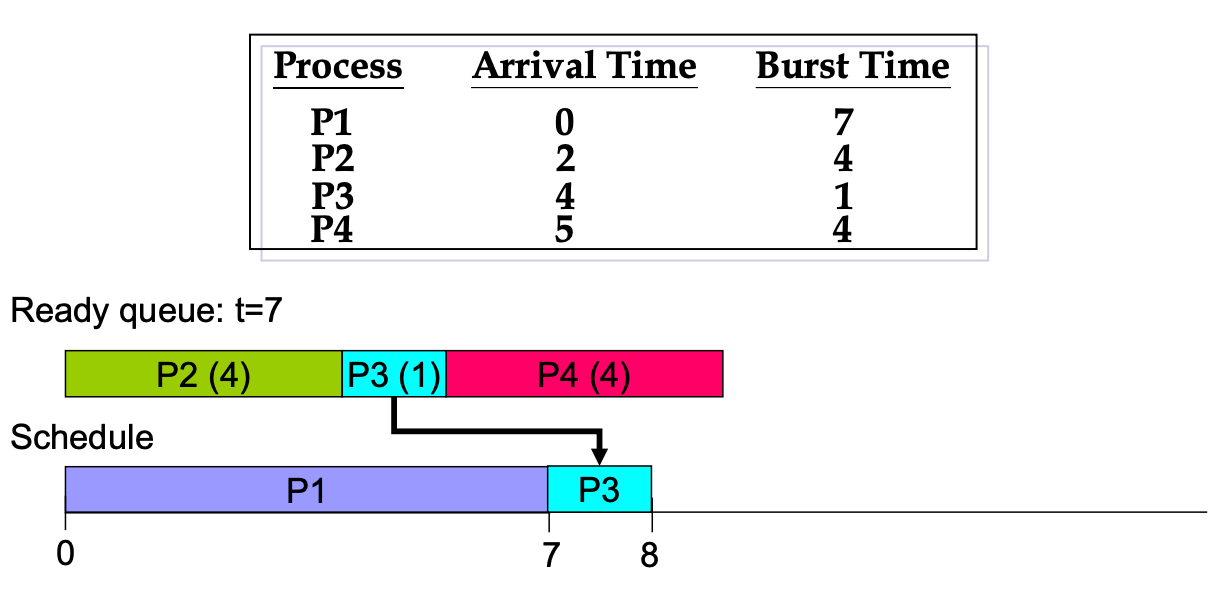
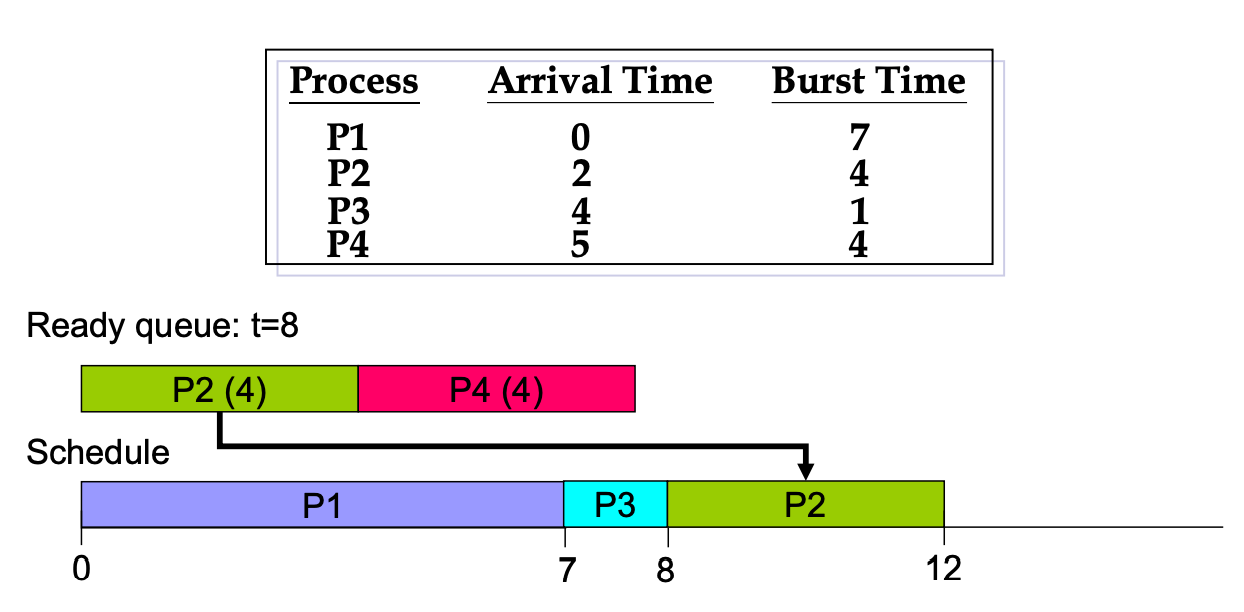

有時候 ready queue 會是空的,那 CPU 就 idle。
AWT 不要算到 CPU idle 的時間。
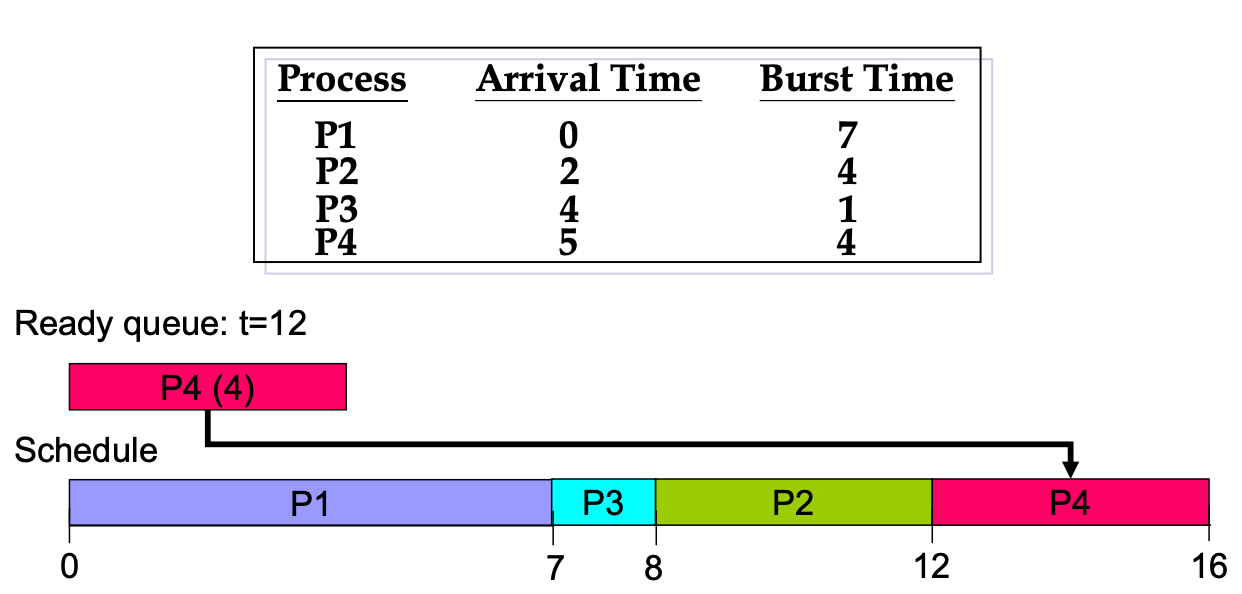
Preemptive example


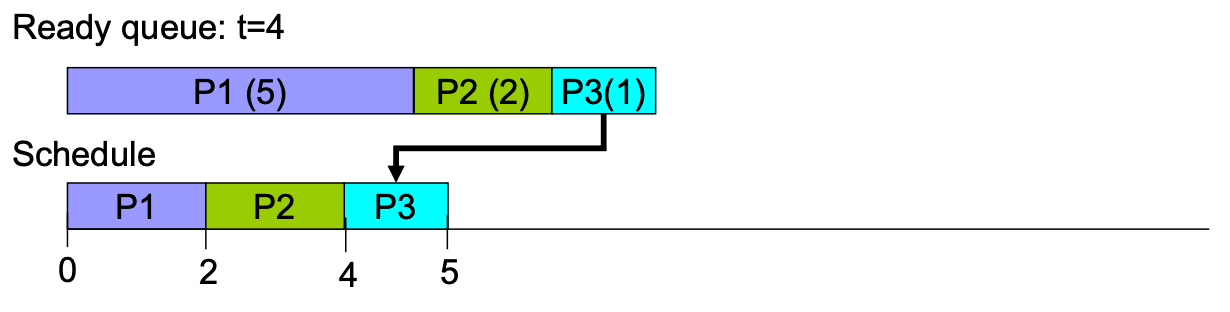
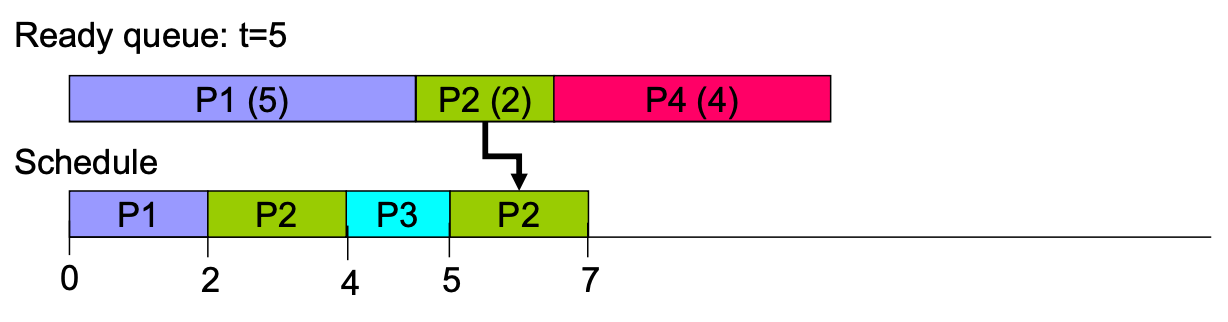
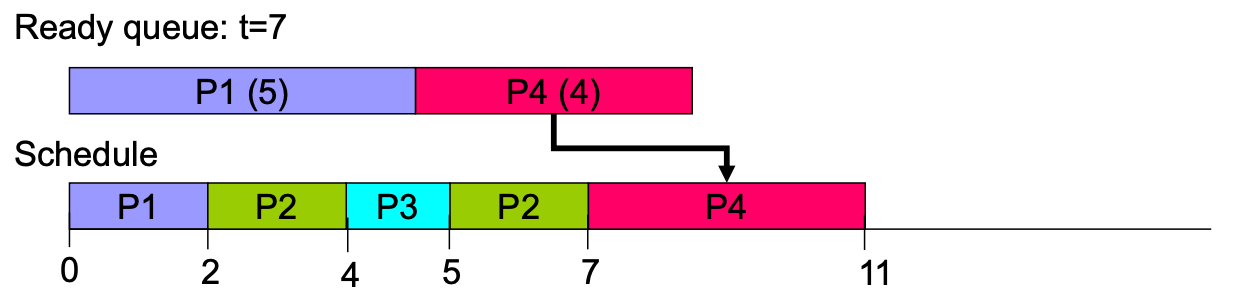
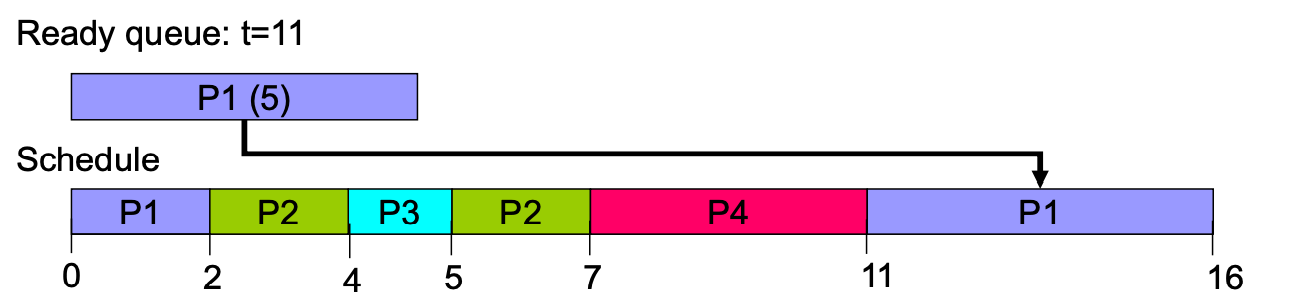

但是因為沒有 future knowledge,所以實作不出來(所以會預測,但是失準就 GG)
Approximate SJF: time series, 用歷史和上次的結果去調整比例來算
\[ \tau_{n+1}=\alpha t_n+(1-\alpha)\tau_n \]
\(\tau\) is the history and \(t\) is the new one
\(\alpha\) usually set as \(1/2\)
Example
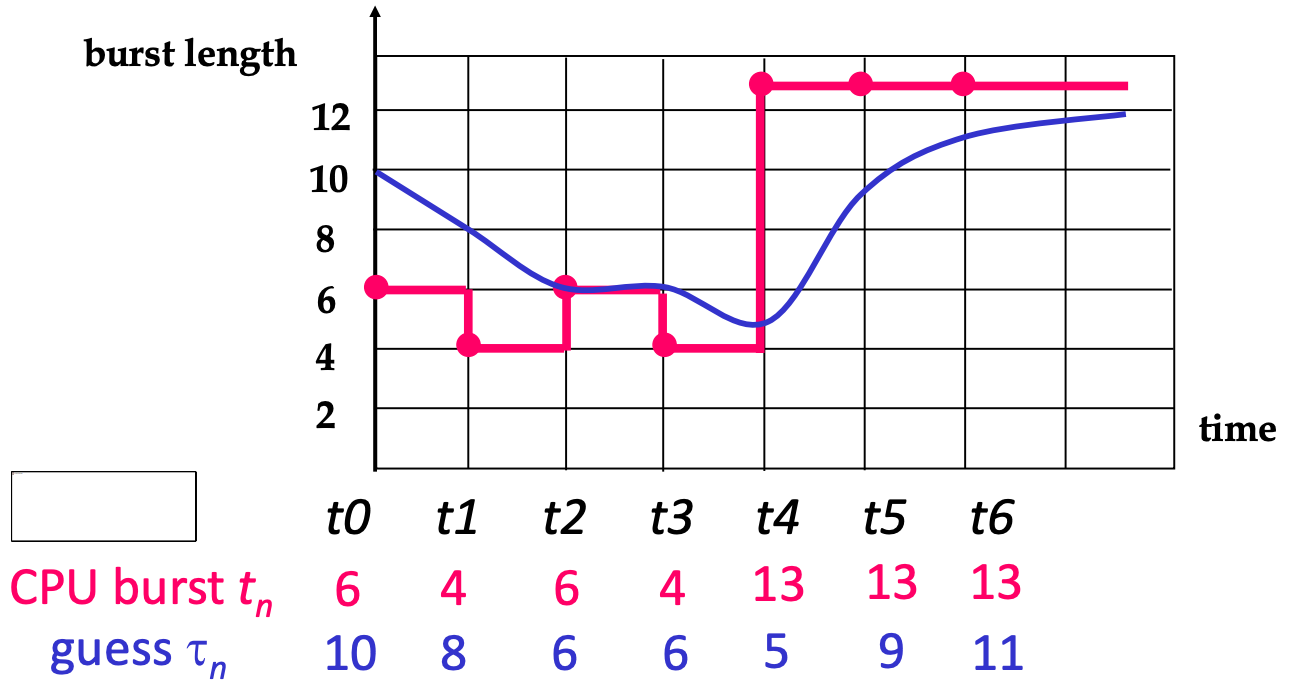
We guess 10 for the first time.
Priority Scheduling
- 每個 process 就有一個 priority 的值(要怎麼決定,啥時決定,都可以),然後就照那個決定
- 最 general 的,上面的兩個也可以說是 priority scheduling
- Problem:
- Starvation: 可能有 process 會永遠沒有排程到
- Solution: aging → 等越久,priority 越高
- Starvation: 可能有 process 會永遠沒有排程到
Round-Robin (RR) Scheduling
每一個 process 都只能執行一定的時間(a.k.a time quantum, usually 10 ~ 100 ms),時間到就被踢出來重新排隊
容易實作,公平
Performance
- TQ too large → FIFO (FCFS)
- 如果不在乎 fairness,那這樣也 OK
- TQ too small → (context switch) overhead increase
- 如果 CPU 沒什麼人在用,那這樣也 OK
- 所以就看系統需求
- TQ too large → FIFO (FCFS)
Example
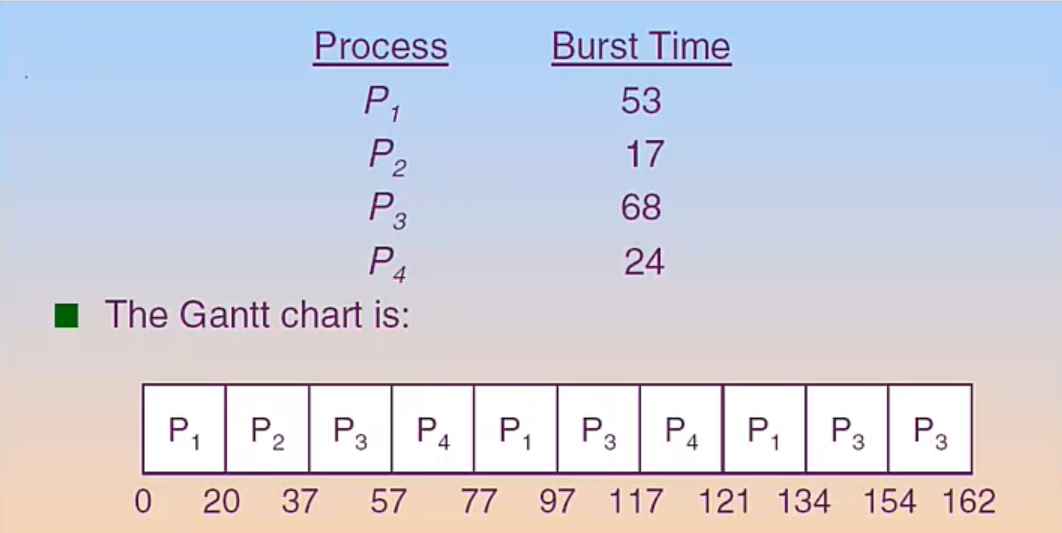
Response time 通常會是最小的,但是 turn around time 通常會很大
Multilevel Queue Scheduling
上面都是 single queue
現在這個有很多 ready queue,一個 process 只會進到其中一個 queue
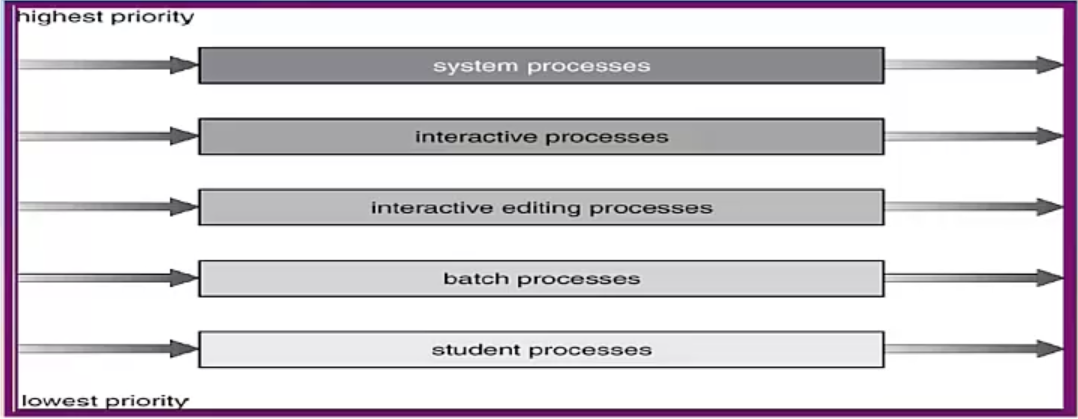
每一個單一 queue 都可以用上面那些解法,我們現在要解決的是怎麼從這麼多 queue 中挑哪一個 queue 來 deqeue
- Fixed priority scheduling: 根據 queue 的 priority 開始挑
- 一樣會有 starvation → 最上面一定要清完才能作下面的,最下面的 queue 可能會排不到
- Time slice: 每一個 queue 會有各自被選中的機率,選中就從那邊 dequeue
- Fixed priority scheduling: 根據 queue 的 priority 開始挑
我們要決定哪一個 process 要加到哪個 queue,但是要在 run 之前就做決定,且加進去就會一直待在裡面,所以可能會東西作一作就變成不應該在那個 queue 的,這樣不好。所以有下面的:
Multilevel Feedback Queue Scheduling
Queues 不會分是要作哪種 process,所以 process 可以在 queues 中移動。(所以叫 feedback)
所以 Higher level 一定都會先被執行(可以作 aging to prevent starvation)
所以我們要做的事情就變成要決定誰會移到哪個 queue(跟上面要做的事完全不同)
幾乎都是根據 I/O 的時間來排,i.e. I/O-bound 的程式會放到上面的 queue。(因為通常 I/O-bound 的程式 CPU 通常會跑比較快)
Example
- 移動條件:如果超過 TQ,就往後踢


所以我們需要決定
- 有幾個 queues
- 每個 queue 用哪種 single queue 的演算法
- 什麼時候 process 要移動
Evaluation Methods
- Deterministic modeling — Given 已知且固定的 input,去比較各個方式(超沒用,通常當例子用)
- Queueing model — 用數學(Queue theory)去算(不是很準,偏向理論)
- Simulation — 模擬然後得到結果(這只有部分功能)
- Implementation — 就實作出來(這已經完整了)
Review Slide (I)
- Preemptive scheduling vs Non-preemptive scheduling?
- Issues of preemptive scheduling
- Turnaround time? Waiting time? Response time? Throughput?
- Scheduling algorithms
- FCFS
- Preemptive SJF, Nonpreemptive SJF
- Priority scheduling
- RR
- Multilevel queue
- Multilevel feedback queue
Special Scheduling Issues
Multi-Processor Scheduling
- 硬體會跟 scheduler 講說他需要多少,就拿給他
- Asymmetric multiprocessing
- 會有一個 centralise 的傢伙在處理誰要去哪
- 就沒有 synchronise 的問題
- 但是會浪費一個 core 在處理
- Symmetric multiprocessing (SMP)
- 直接開搶,所以需要 lock 來處理 synchronise 的問題
Processor affinity
把 process 綁在一個 CPU 上(不同 CPU burst 可能會在不同 core 上)(是為了要處理資料在換 core 的時候資料要重新 cache)
- Type:
- soft affinity
- 如果有空的,就還是會去用
- Hard affinity
- 就算有空的, 也不會用
- soft affinity
- 如果系統的 loading 沒有很高,這是一定有好處沒壞處的,但是如果很多 process 在搶 core,那這就沒啥用了。
NUMA and CPU Scheduling
- NUMA (non-uniform memory access)
- 有些 CPU 離某些 memory 比較近,所以還要把 process 放到離 CPU 比較近的 memory
Load-balancing
Push Migration — 把工作推出去,如果 loading 輕,就用這個去丟工作
Pull Migration — 把工作拉進來,如果 loading 重,就用這個去丟工作
Load balancing often counteracts the benefits of processor affinity (355)
Multi-Core Processor Scheduling
Multi-core Processor — memory stall: 需要等 access memory 的時間
Multi-threaded multi-core systems
- 把上面等 memory access 的時間拿來做事

- Two ways:
- fine-grained: 把所有 stage 的東西都記下來,所以東西不會掉。但是就需要很多硬體資源去記。(快,成本高)
- coarse-grained: 會 flush 不用的東西
Scheduling for Multi-threaded multi-core systems
- Hardware 跟 software 說要幾個 process,然後 software 就給他
- 要怎麼去處理要來的 process(執行在哪個 core)就給 hardware 決定
Real-Time Scheduling
Real-time does not mean speed, but keeping deadlines
- Soft real-time — 希望可以不要 miss deadline,但是 miss 也不會炸開
- Hard real-time — 絕對不能 miss deadline
Real-Time Scheduling Algorithms
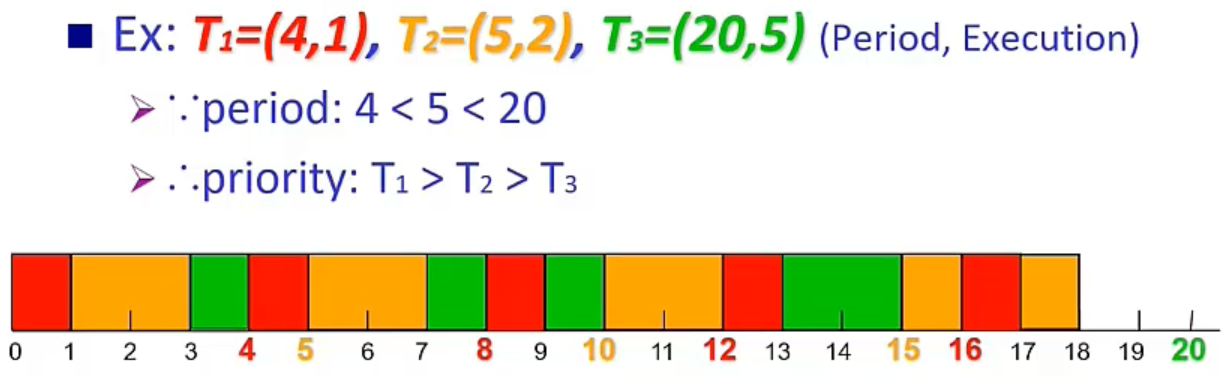
比前面多了 period 的參數 → 每過多久就會重新出現,要在下一次出現前做完這次的。(E.g., (0, 4, 10) → 0,10,20 都會出現一次)
- FCFS — Non-RTS
- Rate-Monotonic (RM) Scheduling
Static (Fixed) → 跑得時候不會改變
Shortest period first
Example
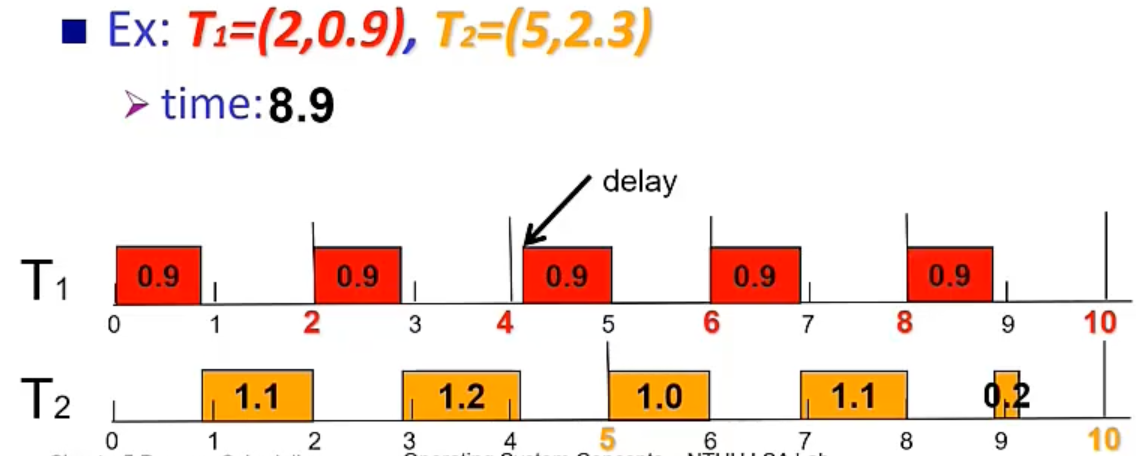
- Earliest-Deadline-First (EDF) algorithm
Dynamic → 跑得時候,每一個的 priority 會變動(因為離 deadline 的時間會變近)
Early deadline first
Miss deadline 會被 bound 住
Example
Review Slide (II)
- What is Processor affinity?
- Real-time scheduler
- Rate-Monotonic
- Earliest deadline first
Scheduling Case Study
Solaris
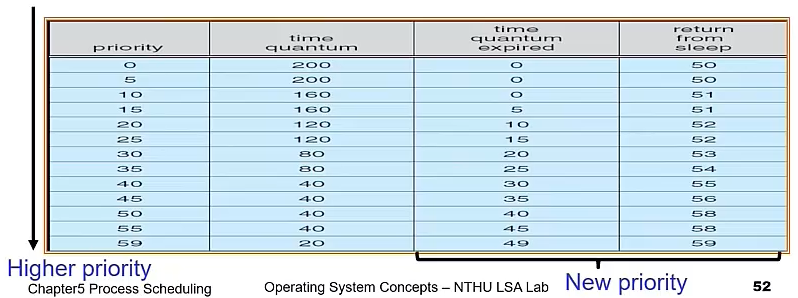
- Priority-based multilevel feedback queue scheduling
- 六個 class — 更像是六個 queue,反正最上面的一定會先做。裡面小的會再自己排序

- Example
- the higher the priority, the
smaller the time slice(因為我們希望 priority 高的,CPU
burst time 是短的,所以很快搶到就要很快放掉)
- Time quantum expired: 只要使用超過你的 time slice,就根據下表調整你的 priority。(因為感覺你是更 CPU burst 的)
- Return from sleep: 從 sleep (i.e. I/O wait) 回來就提升 priority。(因為可以縮短等待時間)
- the higher the priority, the
smaller the time slice(因為我們希望 priority 高的,CPU
burst time 是短的,所以很快搶到就要很快放掉)
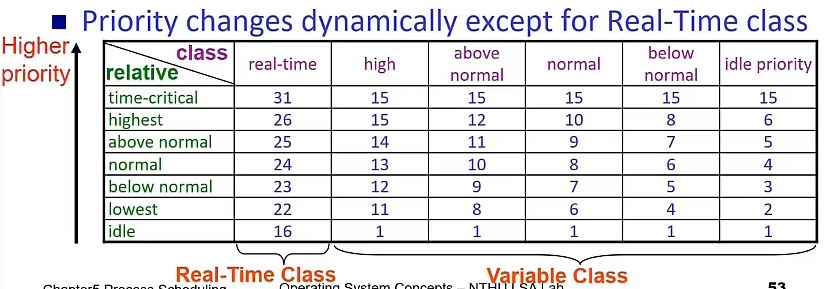
Windows
跟剛剛的差不多
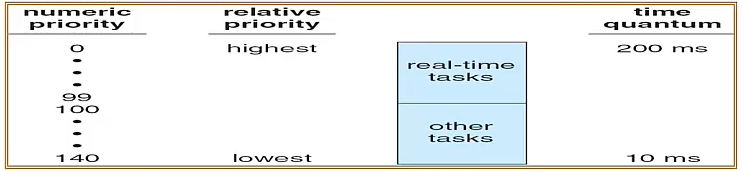
Linux
值越小,priority 越高
分成兩個 class 而已
Priority 高的,分到的 time quantum 越大
⇒ 因為這邊的 time quantum 是 budget 的概念,只要用完就會被丟到 waiting queue
所以他是用比較 fairness 的作法
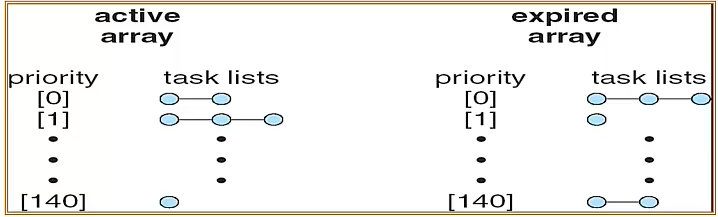
- Algorithm
- 一開始大家都在 active array,然後時間到就被丟到 expired array。(這樣就算是 low priority 的也可以被做到)
- 最後 active array 被清空了就把兩個 array 的指標對調。
- 所以他是一輪一輪的做。
Textbook Questions

QA
- What is CPU-burst?
- 程式正在做 CPU 的 instruction,除此之外的時間都是 I/O-burst
- Preemptive vs. Non-preemptive?
- Preemptive:在 CPU burst 間 scheduler 可以 interrupt 做 scheduling 的動作
- Non-preemptive:在 CPU burst 間 scheduler 不能 interrupt 做 scheduling 的動作(但是 hardware 還是可以 interrupt 的)
此筆記為清華大學周志遠教授作業系統之課堂筆記,所有內容及圖片皆取材於課堂內容。
如內容有誤,歡迎來信 mail@arui.dev。